



 お問い合わせ →
お問い合わせ →  03-6328-2881
03-6328-2881 
今回はアンケート調査の結果を深く分析するうえで役立つ、クラスター分析を紹介します。
クラスター分析とは
定義
似ている性質のものを集めて、かたまり(クラスター)に分類する分析手法です。人やモノ・商品など、さまざまな項目を分類対象にできます。
実施目的
マーケティングにおいてクラスター分析は、次のような目的で実施します。
-
生活者の意識・態度を要約したい
-
アンケート調査で得たデータをもとに、回答者をいくつかのクラスターに分類したい
-
競合や自社ユーザーをいくつかのクラスターに分類したい
-
分類したうえで、ターゲットのプロファイリングをしたい
分析を行う上で前提となる考え方
クラスター
そもそもクラスターとは、「房」「集団」「群れ」のことを指します。
クラスター分析もその名の通り、大量のデータを複数の「集団」に分類する分析手法です。
クラスターに分類していくことを「クラスタリング」とよびます。
類似度
クラスター分析では、サンプル同士がどの程度似ているか、類似度を計算してクラスターに分類します。
この類似度は「サンプル同士の距離」を計算して導きます。
また、サンプルを集約して作成されたクラスター間の距離を計算することで、クラスター同士がどれだけ似ているかを判断できます。
距離の計算方法は分析手法ごとに複数の計算方法があります。
因子分析との組み合わせ
マーケティング実務において、クラスター分析は因子分析と組み合わせて行うことが多くあります。
例えば、生活者をいくつかのクラスターに分類し、自社商品・サービスのターゲットをプロファイリングするような場合です。
分析の流れとしては、まず因子分析を行い、因子分析で導きだした因子得点をクラスター分析に利用します。
実施メリット
大量のデータを分析しやすくする
クラスター分析を実施するメリットは、大量のデータを単純化して理解しやすくすることです。
複数の似たサンプルを集約して1つのクラスターとして扱えるため、データの大まかな特性が把握できます。
アンケート回答者を意識や志向などの心的傾向でクラスタリングし、クラスターごとの集計結果を見ることで、属性やほかの質問とのクロス集計ではわからなかったことまで分析できます。
階層クラスター分析
クラスター分析には、大きく「階層クラスター分析」と「非階層クラスター分析」があります。
階層クラスター分析では、サンプル間の距離が近いものから(=似ているものから)順にクラスタリングされ、以下のようなデンドログラム(樹形図)のようなクラスターを作成する方法です。
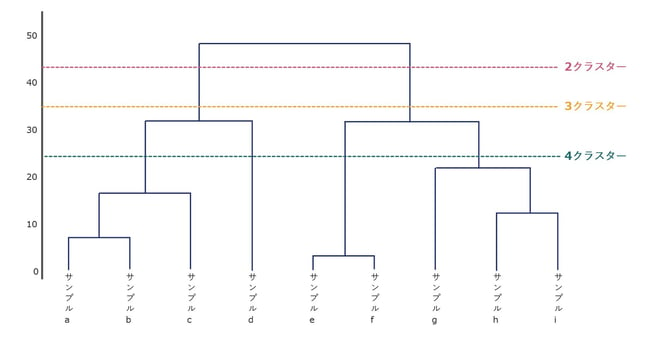
デンドログラム(樹形図)では、サンプル同士の距離が近いもの同士からクラスターを形成します。
図の縦軸はサンプル間、クラスター間の距離を示しています。
図中で上に行くほど、クラスター間の距離が遠く、類似度は低くなります。
分析者がデンドログラム(樹形図)を確認し、どの階層で切るかによって分析するクラスター数を決めることができます。
非階層クラスター分析
非階層クラスター分析では、クラスターは階層的な構造はとりません。
分析者があらかじめ定めたクラスター数でクラスターが形成され、各サンプルがどのクラスターに属しているかがわかります。
非階層クラスター分析の代表的な手法は、k-means法です。互いに距離が近いサンプルは同じクラスターに属すると考え、各サンプルとクラスターの中心との距離を用いてデータをk個に分類する手法です。
手法の違いと特徴
階層クラスター分析と非階層クラスター分析の比較は以下の通りです。
|
|
階層クラスター分析 |
非階層クラスター分析 |
|
アウトプット |
デンドログラム(樹形図) |
クラスター |
|
メリット |
|
|
|
デメリット |
|
|
アウトプットの比較
階層クラスター分析ではデンドログラム(樹形図)が作成されるのに対し、非階層クラスター分析ではそれぞれのサンプルがどのクラスターに属するかがアウトプットとなります。
サンプルaはクラスターA、サンプルbはクラスターB、といったイメージです。
階層クラスター分析のメリット・デメリット
階層クラスター分析では調査後にデンドログラム(樹形図)を見て、好きな数にクラスター数を決めることができるため、事前にデータ構造(適切なクラスター数など)を決める必要がありません。
また、サンプル同士、クラスター同士の類似度を直感的に把握しやすいメリットがあります。
一方で、計算量が多く、サンプルサイズが多い場合の利用に適していません。
また、デンドログラム(樹形図)の解釈が難しく、クラスターの数や意味づけが難しい場合もあります。
非階層クラスター分析のメリット・デメリット
非階層クラスター分析は計算量が少なく、サンプルサイズが大きい場合でも実施できるメリットがあります。
一方で、あらかじめ分類するクラスター数を決める必要がありますが、クラスター数を決めるための明確なルールがないため、分析者の主観や経験が色濃く反映されます。
また、分析ロジックの性質上、分析ごとに最終結果が異なる場合や、外れ値の影響を受けやすいという特徴もあります。
各手法の具体的なアルゴリズムや計算方法の解説
階層クラスター分析のアルゴリズム
まず、それぞれのサンプルが1つのクラスターであると想定します。
-
すべてのクラスター間の距離を計算する
-
距離が一番近い2つを1つのクラスターとして結合する
-
残ったクラスター間の距離の中で、最も近い2つのクラスターを結合するとクラスターが1つ減る。
-
これを繰り返してクラスターの数を減らしていく
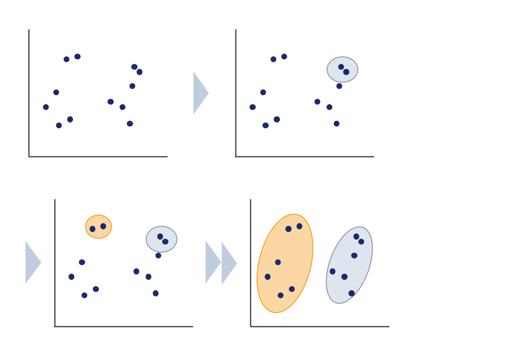
その過程がデンドログラム(樹形図)としてアウトプットされます。
非階層クラスター分析のアルゴリズム
k-means法について紹介します。
-
ランダムに各サンプルにクラスター番号を割り当てる
あらかじめ設定したクラスター数をもとに、まず全サンプルを適当にクラスターに分類してしまいます。
- クラスターの中心を決める
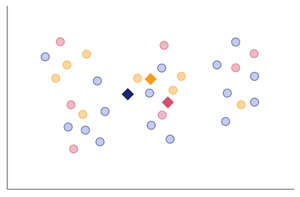
- 各サンプルのクラスター番号を白紙にする
適当に割り当てたクラスター番号を白紙にし、クラスターの中心点だけがわかる状態にします。 -
サンプルに新たなクラスター番号を割り当てる
サンプルごとにすべての中心点との距離を計算し、最も距離が近い代表点のクラスターの番号を新たに割り当てます。
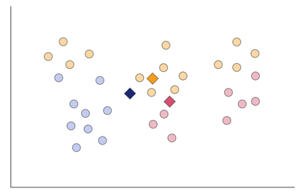
-
上の工程を繰り返す
その後、再度クラスターごとに中心を計算し、すべてのサンプルのクラスター番号を白紙にし、サンプルごとにすべての中心点との距離を計算し、最も距離が近い代表点のクラスターの番号を割り当てる、・・・という工程を繰り返します。
全てのサンプルにおいて、クラスターの番号を白紙にする前と、その後に割り当てられたクラスターの番号が一致すれば終了します。
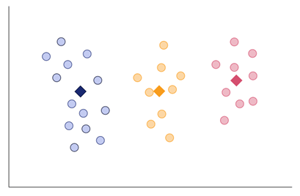
類似度の算出方法とその選択基準
類似度、つまりサンプル間の距離を算出する方法は複数あります。
最も一般的なのはユークリッド距離です。
|
サンプル間の距離算出方法 |
詳細 |
|
ユークリッド距離 |
2点間の直線距離のことで、最も一般的な距離計算方法 |
|
マンハッタン距離 |
碁盤の目の街を歩いたときのように、縦と横を合計した最短距離 |
|
ミンコフスキー距離 |
ユークリッド距離やマンハッタン距離を一般化した計算方法 |
|
マハラノビス距離 |
サンプル間の相関関係を考慮した距離計算方法 |
|
チェビシェフ距離 |
座標次元ごとで求めた差で一番大きいものを2点間の距離とする計算方法 |
階層的クラスタリングの場合、サンプルを結合してできたクラスター間の距離を算出します。
その計算方法も複数あり、最も一般的なのはウォード法です。
|
クラスター間の距離算出方法 |
詳細 |
|
最近隣法 |
クラスター同士で、最も近いサンプル同士の距離 |
|
最遠隣法 |
クラスター同士で、最も遠いサンプル同士の距離 |
|
重心法 |
クラスター内のサンプルの重心(平均) 間の距離 |
|
平均距離法 |
クラスター同士で、すべてのサンプル間の距離の平均 |
|
ウォード法 |
クラスター内のサンプルのばらつきを最小化するように、重心(平均)とそのクラスター内のサンプルとの距離の二乗和を計算する |
実施手順
クラスター分析を行う場合の手順を説明します。
調査設計
クラスター分析を実施する場合、初めの調査設計が大切です。
クラスター分析を実施する目的を明確にしたうえで、分析可能な質問設計を行う必要があります。
因子分析を合わせて行う場合は、ある程度因子を想定して調査票に反映する必要もあります。
データ集計・分析
アンケート調査で得たデータを集計し、クラスター分析を行います。データをクラスタリングし、解釈できる形に整えます。
クラスター解釈
クラスターが作成されたら、各クラスターにどのようなサンプルが分類されているか、それぞれの特徴は何かなどを解釈していきます。
年代や性別などの属性情報、他のアンケート設問の回答と掛け合わせることで、より詳しく各クラスターを分析できます。
分析結果の活用
分析して終わりとなっては意味がありません。
分析後は各クラスターの分析結果をさまざまなアクションに活用していきます。
それぞれのクラスターに効果的な訴求メッセージで広告クリエイティブを作成する、キャンペーンを実施する、特定のクラスターに属する顧客の心理を深く理解するためインタビュー調査を行うなど、活用の幅は非常に広いです。
事前に分析結果をどのように活用するか、関係者間でも確認しておきましょう。
クラスター分析の活用事例
顧客のセグメンテーションとプロファイリングに利用
あるメーカーが社会問題、地球環境に配慮した新しいアパレルブランドを立ち上げました。
既存ブランドの顧客も新ブランドを購入してくれていますが、ブランドコンセプトの違いから、これまで獲得できていなかった顧客層の獲得が必要だと考えています。
ターゲット層の目星をつけるため、クラスター分析を行いました。
まずは、28項目の社会問題への関心度や購買意識を調査し、因子分析で「エコ・地球環境」「流行・最先端」の2つの因子を抽出しました。
その後、抽出した2因子の因子得点から対象者の「クラスター分析」を行ない、4つのセグメントに分類し、各セグメントの特徴にあったクラスター名称をつけました。
最もボリュームが多い「クラスター1」を第一ターゲット層、「エコ・地球環境」因子が高い「クラスター3」を第二ターゲット層としてプロファイルを作成し、その後マーケティング施策に活用しました。
注意点
客観的な結果とは言い切れない
非階層クラスター分析も階層クラスター分析も、クラスターの意味づけに分析者の主観が大きく影響するため、客観的な結果とは言い切れません。
あくまでも大量のデータを分析しやすくまとめる分析手法だと認識しましょう。
分析者に求められる専門性
分析者の主観が結果に大きく影響するため、分析結果の適切さは分析者のスキルや経験によって左右されます。
分析者には、調査設計・分析手法・消費者への深い理解が求められます。
目的の明確化
どの分析手法にも言えることですが、分析結果をアクションにつなげるために、どのように活用するのか、分析目的を明確にイメージしておきましょう。
まとめ
クラスター分析とは、サンプルごとの類似度を計算し、似ているサンプルを集めて、クラスターに分類する分析手法です。
マーケティング実務においては、因子分析と組み合わせて実施することが多くあります。
実施メリットは、大量のデータをいくつかの意味を持ったセグメントに分類し、分析しやすくすることです。
クラスター分析には、階層クラスター分析と非階層クラスター分析があり、それぞれの特徴を把握して手法を選択する必要があります。
ネオマーケティングでは、クラスター分析からマーケティング施策の実行まで幅広くご支援しています。
クラスター分析実施をご検討の方はお気軽にご相談ください。
ネオマーケティングは国内約2889万人のアンケート会員を保有するパネルネットワークを構築、ご希望の調査対象者にリサーチを実施することが可能です。
マーケティング課題を解決し、必要なデータを取得するための調査設計から、調査結果の活用まで、伴走してご支援しています。リサーチを起点に、デジタルマーケティング、PR、ブランディング支援も行っています。
まずはネオマーケティングのサービス資料をご覧ください。

ご相談・お問い合わせ
以下のフォームよりお気軽にお問い合わせください。
お急ぎの方は、03-6328-2881までお電話ください。コンサルタントがすぐに対応します。
カテゴリー一覧
マーケティングリサーチならネオマーケティングにお任せください!
課題解決・目的達成のために、お客様が何を求めているのかということを常に考え一歩先のご提案をいたします。
リサーチが初めての方へ
リサーチが初めての方はこちらをご覧ください。
マーケティングリサーチとは何か。
どのように進めていくのか。わかりやすく解説いたします。
ネオマーケティングの特徴
ネオマーケティングはお客様の抱える課題や調査目的、その背景を充分にヒアリングした上で、
課題解決・目的達成のために、お客様が何を求めているのかということを
常に考え一歩先のご提案をいたします。